Redis를 사용하는 이유

이 글에서는 Redis의 탄생 배경과 싱글 스레드 동작 원리, 그리고 RDB/AOF 및 클러스터링을 통해 데이터 영속성과 고가용성을 확보하는 핵심 아키텍처에 대해 설명합니다.
1. 개요
최근 기술 면접에서 “왜 Redis를 사용하나요?”라는 질문을 받았습니다.
저는 아래와 같이 대답했습니다.
- Redis는 인메모리(In-Memory) 데이터 저장소입니다.
- 디스크(Disk)에 데이터를 저장하는 데이터베이스와 달리 메모리에 데이터를 저장하므로 빠릅니다.
- Key-Value 형태로 데이터를 저장합니다.
- 캐싱, 세션 관리 등의 목적으로 주로 사용됩니다.
위 답변이 틀린 것은 아니지만, 면접관이 정말 궁금했던 것은 뻔한 답변이 아니라, 제가 Redis의 특성을 얼마나 깊이 이해하고 상황에 맞게 올바르게 사용하는지에 대한 것이었습니다.
이어진 후속 질문은 다음과 같았습니다.
- “Redis가 데이터를 메모리에 저장하는 방식은 관계형 데이터베이스와 어떤 차이가 있나요?”
- “Redis는 어떻게 데이터 영속성(Persistence)을 보장하나요?”
AOF, RDB 같은 키워드는 들어봤지만, 각 방식의 동작 원리나 장단점을 명확히 설명하지는 못했습니다. 면접이 끝나고 나서야, 여러 프로젝트에 Redis를 사용했음에도 그 내부 동작 원리를 깊이 있게 공부하지 않았다는 사실에 아쉬움을 느꼈습니다.
이 블로그를 시작한 계기이기도 합니다. 특정 기술을 도입할 때, ‘어떻게’ 사용하는지를 넘어 ‘왜’ 그렇게 동작하는지 충분히 이해하고 사용하자는 다짐 말입니다.
그래서 이번 글에서는 Redis의 등장 배경부터 주요 특징, 그리고 핵심적인 내부 동작 원리까지 자세히 다뤄보려고 합니다.
2. Redis의 등장 배경
2.1. 디스크 기반 데이터베이스의 한계
Redis가 등장하기 전, 대부분의 데이터베이스(예: MySQL, PostgreSQL 등)는 Disk I/O를 기반으로 동작했습니다.
2009년, LLOOGG라는 서비스를 개발하던 살바토레 산필리포(Salvatore Sanfilippo)는 실시간으로 사용자의 페이지 방문을 추적하고, 최근 방문자 목록을 보여주는 기능을 구현해야 했습니다.
그는 당시 보편적으로 사용되던 MySQL에 방문 이벤트를 기록하고 조회하는 방식을 사용했습니다. 하지만 서비스 트래픽이 증가하자 심각한 성능 저하를 겪었습니다.
- 비효율적인 쓰기: 페이지가 조회될 때마다 데이터베이스에
INSERT연산을 수행해야 했습니다. - 비효율적인 읽기: 최근 방문자 10,000명을 보여주기 위해, 매번 디스크에 저장된 방대한 테이블에서
SELECT쿼리로 정렬과 필터링을 수행해야 했습니다.
살바토레는 이 문제를 해결하기 위해 디스크 대신 메모리에서 데이터를 처리하는 방법을 고안했고, 이것이 바로 Redis의 시작이었습니다.
2.2. 자료구조를 이해하는 데이터베이스
Redis가 성공할 수 있었던 또 다른 핵심 이유는 자료구조를 이해하는 데이터베이스라는 점입니다.
이 개념이 모호하게 들릴 수 있으니, ‘특정 페이지에 가장 최근에 접속한 사용자 10명’을 조회하는 예시를 통해 알아보겠습니다.
MySQL의 접근 방식: 조회 시점에 정렬
일반적인 RDBMS(MySQL)를 사용한다면 과정은 다음과 같습니다.
- 저장: 사용자가 방문할 때마다
visits테이블에 데이터를 계속 쌓습니다. (INSERT) - 조회: 최근 10명을 보여달라는 요청이 오면, 수만, 수천만 개의 데이터 중에서 생성 시간을 기준으로 정렬한 뒤 상위 10개를 잘라냅니다.
1
2
3
4
SELECT user_id
FROM visits
ORDER BY created_at DESC
LIMIT 10;
이 방식의 문제는 데이터가 많아질수록 조회 속도가 현저히 느려진다는 점입니다. 10명을 보기 위해 DB는 매번 전체 데이터를 훑거나 인덱스를 타며 복잡한 정렬 작업을 수행해야 하기 때문입니다.
Redis의 접근 방식: 저장 시점에 순서 관리
반면, Redis는 List(리스트)라는 자료구조를 지원합니다. 살바토레는 이 점을 이용해 데이터를 저장하는 시점에 이미 순서를 관리하는 방식을 택했습니다.
- LPUSH (넣기): 새로운 방문자가 오면 리스트의 맨 앞(Left)에 데이터를 밀어 넣습니다.
- LTRIM (다듬기): 리스트의 길이를 10개로 유지하기 위해, 10번째 이후의 데이터는 즉시 잘라버립니다.
1
2
3
4
5
# 1. 리스트 맨 앞에 새 사용자 추가
LPUSH latest_visits "New_User"
# 2. 리스트를 0번부터 9번 인덱스까지만 남기고 나머지는 삭제
LTRIM latest_visits 0 9
이렇게 하면 Redis 메모리 안에는 항상 ‘최신 방문자 10명’만 정확히 유지됩니다.
조회할 때는 복잡한 정렬 없이 리스트에 있는 데이터를 그대로 가져오기만 하면 됩니다. 데이터가 100만 건이든 1억 건이든, Redis는 항상 일관되게 빠른 속도로 10명의 데이터를 반환할 수 있습니다.
이것이 바로 “서버가 자료구조(List)를 이해한다”는 Redis의 핵심 철학입니다.
3. Redis의 주요 특징
이제 등장 배경을 알았으니, Redis의 주요 특징들을 하나씩 살펴보겠습니다.
3.1. 인메모리(In-Memory) 기반 저장소
Redis는 모든 데이터를 메모리(RAM)에 저장합니다. 디스크를 탐색(Seek)하는 과정이 필요 없기 때문에 데이터 접근 속도가 마이크로초(µs) 단위로 매우 빠릅니다. 이는 캐싱(Caching), 실시간 랭킹 등 고성능이 요구되는 작업에 최적화되어 있음을 의미합니다.
3.2. 다양한 자료구조 지원
Redis는 String, List, Set, Hash, Sorted Set 등 다양한 자료구조를 키(Key)와 값(Value) 형태로 지원합니다.
- 개발자가 데이터를 애플리케이션으로 가져와서(Get) 가공한 뒤 다시 저장하는(Put) 비효율적인 과정을 거칠 필요가 없습니다.
- “리스트의 3번째 요소를 삭제하라”와 같은 명령을 서버에 직접 내림으로써, 네트워크 트래픽(Overhead)을 획기적으로 줄이고 애플리케이션 코드를 간결하게 유지할 수 있습니다.
위는 Redis의 기본적인 특징이며, 아래는 Redis를 사용할 때 반드시 알아야 할 핵심 특징들입니다.
3.3. 싱글 스레드(Single Threaded) 모델
이 부분은 Redis의 동시성 제어를 이해하는 데 가장 중요한 핵심입니다. Redis는 사용자의 명령을 처리하는 핵심 로직이 싱글 스레드(Single Threaded)로 동작합니다.
- 원자성(Atomic Operations): 한 번에 하나의 명령어만 실행하므로, 어떤 명령어가 실행되는 동안 다른 명령어가 끼어들 수 없습니다. 이 덕분에 개발자는 Race Condition(경쟁 상태)에 대한 복잡한 고민 없이
INCR,DECR같은 연산을 안전하게 수행할 수 있습니다. - 높은 처리량(High Throughput): “싱글 스레드인데 어떻게 동시에 수만 명의 요청을 처리할까?” 라는 의문이 들 수 있습니다. Redis 6.0부터는 네트워크 I/O 처리에 멀티 스레드를 도입하여(I/O Multiplexing), 여러 클라이언트의 요청을 동시에 받고 응답을 보낼 수 있습니다. 하지만 여전히 사용자의 명령어를 실행하는 부분은 싱글 스레드로 유지하여 원자성을 보장합니다.
3.4. 데이터 영속성(Persistence) 지원
메모리는 전원이 꺼지면 데이터가 사라지는 휘발성(Volatile) 장치입니다. Redis는 이를 보완하기 위해 두 가지 영속성 옵션을 제공합니다.
- RDB (Snapshot): 특정 시점의 메모리 상태를 그대로 디스크에 스냅샷으로 저장합니다.
- AOF (Append Only File): 모든 쓰기 작업을 로그 파일에 기록하여, 재시작 시 이 로그를 다시 실행해 데이터를 복구합니다.
3.5. 고가용성(High Availability) 및 확장성
단일 서버의 한계를 넘어서기 위한 다양한 아키텍처를 지원합니다.
- Replication: Master-Replica 구조로 데이터를 복제하여 읽기 성능을 확장하고 데이터 가용성을 높입니다.
- Sentinel: 장애 발생 시 자동으로 Master를 교체하는 Failover(장애 조치) 기능을 제공합니다.
- Cluster: 데이터를 여러 노드에 분산 저장(Sharding)하여 수평적 확장을 가능하게 합니다.
위의 특징들을 바탕으로, 4장부터는 Redis의 동작 방식에 대해 더 깊이 알아보겠습니다.
4. 싱글 스레드(Single Threaded) 모델과 동작 원리
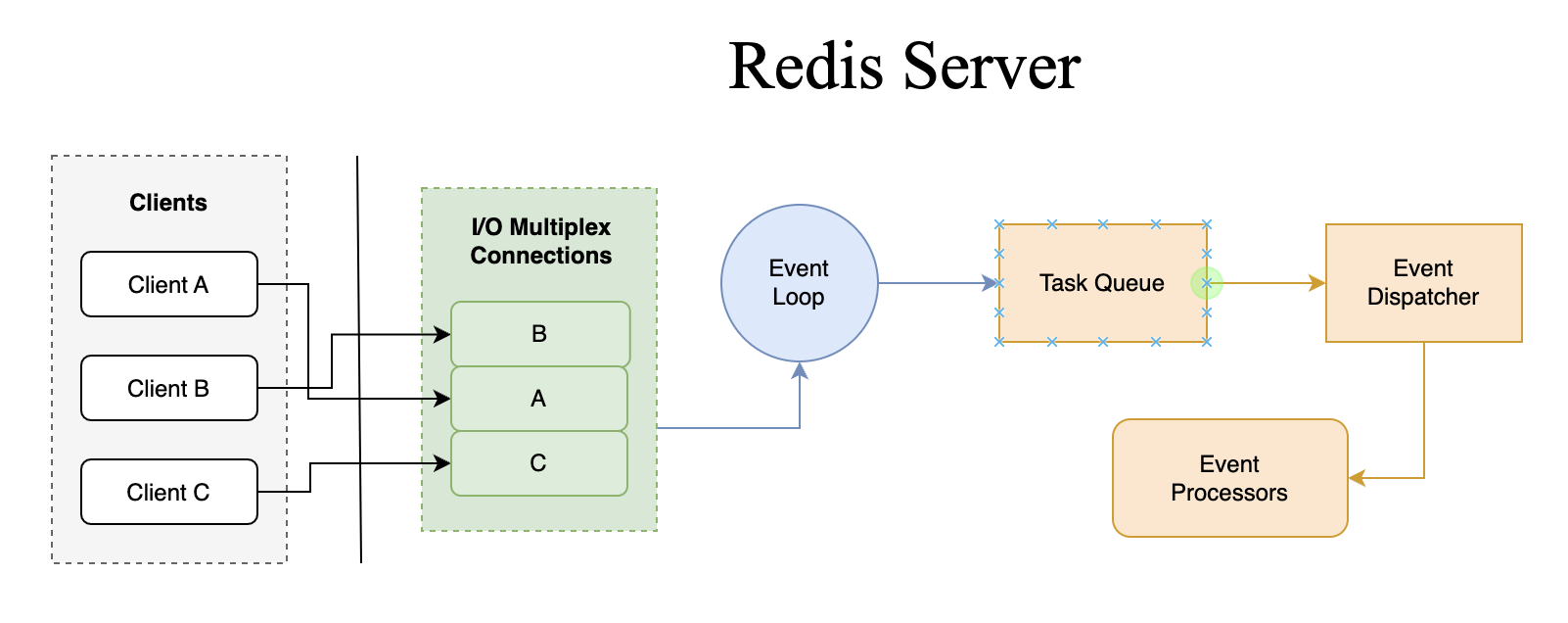 Redis Overall Architecture
Redis Overall Architecture
Redis를 싱글 스레드 모델이라고 부르는 이유는, 사용자의 명령을 실행하는 핵심 로직이 단일 스레드에서 순차적으로 처리되기 때문입니다. 이는 Node.js의 이벤트 루프 모델과 유사하지만, Redis는 인메모리 데이터 연산에 더욱 최적화된 구조를 가집니다.
4.1. 어떻게 하나의 스레드로 수만 건의 요청을 처리할까?
“싱글 스레드면 한 번에 하나밖에 처리하지 못해 느리지 않을까?” 라는 의문이 들 수 있습니다. 하지만 Redis는 I/O 멀티플렉싱(Multiplexing) 기술을 사용해 이 문제를 극복합니다.
정확히 말하면, Redis 6.0부터는 클라이언트의 요청을 받고 응답하는 네트워크 I/O 처리 부분에 멀티 스레드를 도입했습니다. 여러 스레드가 동시에 I/O를 처리한 후, 실행할 명령들을 명령 큐(Command Queue)에 순서대로 쌓습니다. 그러면 이벤트 루프(Event Loop)를 도는 핵심 싱글 스레드가 큐에서 명령을 하나씩 꺼내어 순차적으로 실행하고, 실행 결과를 다시 I/O 스레드에 전달해 클라이언트에게 응답하는 구조입니다.
즉, 시간이 많이 소요되는 I/O 작업을 여러 스레드가 병렬로 처리하여 효율을 높이고, 실제 데이터의 상태를 변경하는 중요한 커맨드 실행은 싱글 스레드로 유지하여 원자성과 데이터 일관성을 보장하는 것입니다.
4.2. 왜 커맨드 실행은 싱글 스레드를 유지할까?
Redis 개발진은 멀티 스레드의 복잡성을 감수하는 것보다 싱글 스레드의 단순함이 더 효율적이라고 판단했습니다.
- CPU가 병목 지점이 아니다: Redis의 작업은 대부분 메모리 접근과 단순 연산입니다. 성능의 한계는 CPU 처리 속도가 아니라 메모리 대역폭(Memory Bandwidth)이나 네트워크 I/O에서 먼저 발생합니다.
- Context Switching 비용 없음: 멀티 스레드 환경에서는 스레드 간 전환(Context Switching)에 CPU 자원이 소모됩니다. 싱글 스레드는 작업 전환 비용 없이 오로지 명령 처리에만 집중할 수 있습니다.
- Lock으로 인한 오버헤드 불필요: 멀티 스레드 환경에서는 데이터 동기화를 위해 Mutex 같은 Lock을 사용해야 합니다. 이는 구현을 복잡하게 만들고 성능 저하를 유발할 수 있습니다. 싱글 스레드 모델은 이러한 잠금 장치가 필요 없어 구조가 단순하고 빠릅니다.
4.3. 동작의 특징: 원자성(Atomicity)과 블로킹(Blocking)
이 구조는 장단점이 명확합니다.
- 장점: 원자성 보장 (Atomic)
- Redis는 한 번에 하나의 명령만 수행하므로,
INCR(값 증가) 같은 명령어가 실행되는 도중에 다른 명령어가 끼어들 수 없습니다. 즉, 별도의 Lock 처리 없이도 데이터 정합성(Race Condition 방지)이 자연스럽게 보장됩니다.
- Redis는 한 번에 하나의 명령만 수행하므로,
- 단점: Stop-the-World (Blocking)
- 단일 스레드이기 때문에, 오래 걸리는 명령 하나가 실행되면 그 뒤의 모든 요청이 대기해야 합니다. 예를 들어, 수백만 개의 키가 저장된 상태에서
KEYS *(모든 키 조회) 같은 명령을 실행하면, 그 작업이 끝날 때까지 전체 서비스가 일시적으로 멈출 수 있습니다.
- 단일 스레드이기 때문에, 오래 걸리는 명령 하나가 실행되면 그 뒤의 모든 요청이 대기해야 합니다. 예를 들어, 수백만 개의 키가 저장된 상태에서
따라서 프로덕션 환경에서 Redis를 사용할 때는
KEYS대신SCAN명령을 사용하고, 시간 복잡도가 O(N) 이상인 명령어 사용에 각별히 주의해야 합니다.
5. 데이터 영속성 지원
Redis는 인메모리 저장소이지만, 서버가 예기치 않게 종료되더라도 데이터를 보존할 수 있도록 영속성(Persistence) 옵션을 제공합니다.
5.1. RDB (Redis Database / Snapshotting)
RDB는 특정 시점의 메모리 데이터를 통째로 디스크에 스냅샷(Snapshot) 파일로 저장하는 방식입니다. SAVE 설정에 따라 “매 1시간마다” 또는 “100번의 쓰기 작업이 발생하면” 같은 조건으로 자동 저장을 수행할 수 있습니다.
작동 원리: Fork와 Copy-on-Write (COW)
Redis는 어떻게 수 기가바이트의 데이터를 디스크에 저장하면서 동시에 사용자의 요청을 처리할 수 있을까요? 그 비밀은 OS의 fork() 시스템 콜과 Copy-on-Write (COW) 기술에 있습니다.
- Fork: 스냅샷 저장 시점이 되면, Redis는 현재 프로세스(Parent)를 복제하여 자식 프로세스(Child)를 생성합니다.
- Snapshot Writing: 자식 프로세스는 그 시점의 메모리 상태를 그대로 디스크 파일(
dump.rdb)로 쓰는 작업을 전담합니다. 이 동안 부모 프로세스는 다른 작업에 영향을 받지 않습니다. - Copy-on-Write: 스냅샷을 저장하는 동안 부모 프로세스는 계속해서 사용자의 요청을 처리합니다. 만약 이때 데이터 변경(Write)이 발생하면, OS는 원본 데이터가 담긴 메모리 페이지를 복사한 뒤, 복사본에 변경사항을 반영합니다. 덕분에 자식 프로세스는 복제된 시점의 데이터를 일관성 있게 저장할 수 있습니다.
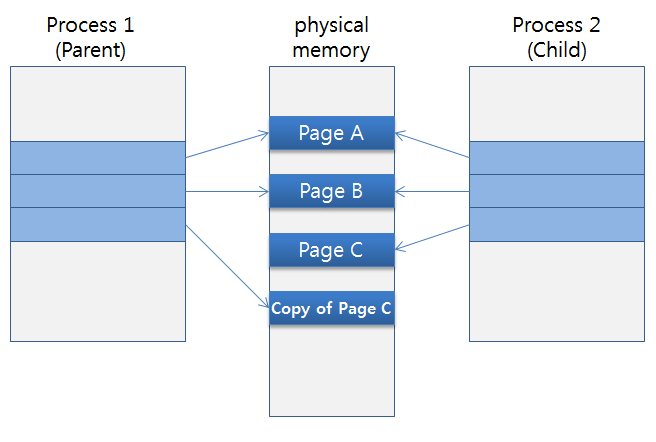 Copy-on-Write 동작 방식
Copy-on-Write 동작 방식
이 과정에서 변경이 발생하는 페이지 수만큼 추가 메모리가 사용될 수 있습니다.
RDB의 특징
- 장점:
- 빠른 백업 및 복구: RDB 파일은 바이너리 형태로 압축되어 저장되므로 파일 크기가 작고, 재시작 시 로딩 속도가 AOF에 비해 매우 빠릅니다.
- 성능 영향 최소화: 자식 프로세스가 스냅샷 생성을 전담하므로, 부모 프로세스는 서비스 요청 처리에 집중할 수 있습니다.
- 단점:
- 데이터 유실 가능성: 마지막 스냅샷 이후 서버가 종료되면 해당 시점까지의 변경분은 모두 유실됩니다. 데이터 무결성이 매우 중요한 서비스에는 적합하지 않을 수 있습니다.
fork()로 인한 지연: 데이터셋이 클 경우fork()시스템 콜 호출 시 일시적인 지연(블로킹)이 발생할 수 있습니다.
5.2. AOF (Append Only File)
AOF는 모든 쓰기/수정 명령을 로그 파일에 순차적으로 기록하는 방식입니다. Redis가 재시작될 때 이 로그 파일을 순서대로 재실행하여 데이터를 복구합니다.
작동 원리 및 AOF Rewrite
모든 명령이 기록되면 AOF 파일이 비대해질 수 있습니다. 이를 방지하기 위해 Redis는 AOF Rewrite 기능을 제공합니다. Rewrite는 현재 메모리 상태를 기준으로 데이터를 복구하는 데 필요한 최소한의 명령어들로 구성된 새로운 AOF 파일을 생성하는 과정입니다. 이 과정 역시 RDB와 마찬가지로 fork()를 통해 자식 프로세스가 안전하게 수행합니다.
AOF의 특징
- 장점:
- 높은 데이터 안정성:
appendfsync설정에 따라 쓰기 명령이 디스크에 기록되는 주기를 조절할 수 있어 데이터 유실 위험이 RDB보다 훨씬 적습니다. - 로그 분석 용이: 모든 명령어 기록이 텍스트 파일로 저장되어 사람이 읽고 분석하기 쉽습니다.
- 높은 데이터 안정성:
- 단점:
- 파일 크기 및 복구 시간: RDB에 비해 파일 크기가 크고, 재시작 시 복구 시간이 더 오래 걸릴 수 있습니다.
- 성능 저하 가능성:
appendfsync설정에 따라 쓰기 성능이 RDB보다 저하될 수 있습니다.
appendfsync 옵션
always: 모든 쓰기 명령마다 디스크에 동기화합니다. 가장 안전하지만 성능이 가장 느립니다.everysec(기본값): 1초마다 쓰기 명령을 모아 디스크에 동기화합니다. 성능과 안정성 사이의 좋은 균형을 제공하며, 최대 1초 분량의 데이터가 유실될 수 있습니다.no: OS가 디스크에 쓰는 시점을 결정하도록 위임합니다. 가장 빠르지만 데이터 유실 위험이 가장 큽니다.
5.3. RDB와 AOF, 무엇을 선택해야 할까?
| 구분 | RDB (Snapshotting) | AOF (Append Only File) |
|---|---|---|
| 데이터 보존성 | 낮음 (마지막 스냅샷 이후 데이터 유실) | 높음 (최대 1초 분량 데이터 유실 가능) |
| 백업/복구 속도 | 빠름 (파일 크기가 작고, 로딩이 빠름) | 느림 (파일이 크고, 모든 명령을 재실행) |
| 성능 | 높음 (자식 프로세스가 처리) | 상대적으로 낮음 (디스크 쓰기 빈도에 따라 다름) |
| 파일 크기 | 작음 (압축된 바이너리 파일) | 큼 (모든 쓰기 명령 기록) |
| 적합한 용도 | - 데이터 유실에 상대적으로 덜 민감한 경우 - 빠른 백업 및 복구가 중요한 경우 - 캐시 데이터 | - 데이터 무결성이 매우 중요한 경우 - 장애 발생 시 유실을 최소화해야 하는 경우 |
Redis 4.0부터는 AOF-RDB 하이브리드 모드를 지원합니다. AOF Rewrite 시, 파일 앞부분에는 RDB 스냅샷을 기록하고 뒷부분에는 그 이후의 쓰기 명령을 추가하여, 빠른 복구 속도와 높은 데이터 안정성을 동시에 확보할 수 있습니다. 특별한 이유가 없다면 이 하이브리드 모드를 사용하는 것이 현대적인 Redis 운영에 가장 권장됩니다.
6. Redis의 고가용성 및 확장성
Redis를 단일 서버로 사용할 수도 있지만, 대규모 서비스에서는 안정성과 성능을 위해 다양한 아키텍처를 활용합니다.
6.1. Replication (복제)
Redis는 Master-Replica Replication을 지원하여 데이터를 복제하고 읽기 작업을 분산합니다.
- Master: 쓰기 작업을 처리하는 주 서버입니다.
- Replica: Master의 데이터를 실시간으로 복제하여 읽기 작업을 처리하는 보조 서버입니다.
Master는 쓰기 작업에 집중하고, 여러 대의 Replica가 읽기 요청을 나눠 처리함으로써 전체 시스템의 부하를 분산하고 처리량을 높이는 Read-Write Splitting 구조를 쉽게 구축할 수 있습니다.
RDB 기반 전체 동기화 과정
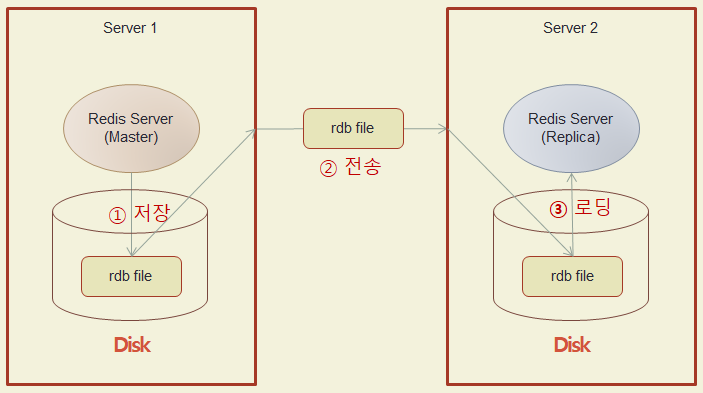 Master-Replica 동기화 과정
Master-Replica 동기화 과정
Replica가 처음 Master에 연결될 때 다음과 같은 전체 동기화(Full Synchronization) 과정이 발생합니다.
- 스냅샷 생성: Replica가 연결을 요청하면, Master는
fork()를 통해 자식 프로세스를 생성하여 현재 메모리 상태를 RDB 스냅샷 파일로 만듭니다. 이 동안 Master는 들어오는 쓰기 작업을 별도의 버퍼에 임시 저장합니다. - 스냅샷 전송: Master는 생성된 RDB 파일을 Replica로 전송합니다.
- 데이터 로드: Replica는 자신의 데이터를 모두 비운 뒤, 받은 RDB 파일을 로드하여 Master와 동일한 상태로 만듭니다.
- 버퍼 데이터 전송: 스냅샷 생성 중에 Master의 버퍼에 쌓여있던 쓰기 명령들을 Replica에게 전송하여 반영합니다.
- 실시간 변경분 전파: 초기 동기화가 완료된 후에는, Master에서 발생하는 모든 쓰기 명령이 실시간으로 Replica에게 전파됩니다.
6.2. Sentinel (감시 및 자동 장애 조치)
Master-Replica 구조에서 Master 서버가 다운되면 쓰기 작업이 불가능해집니다. 이를 해결하기 위해 Redis는 Sentinel이라는 고가용성 솔루션을 제공합니다.
Sentinel은 Master 서버의 장애를 감시하고, 장애 발생 시 자동으로 Replica 중 하나를 새로운 Master로 승격시켜 서비스 중단을 최소화하는 자동 장애 조치(Automatic Failover)를 수행합니다.
Sentinel 동작 원리
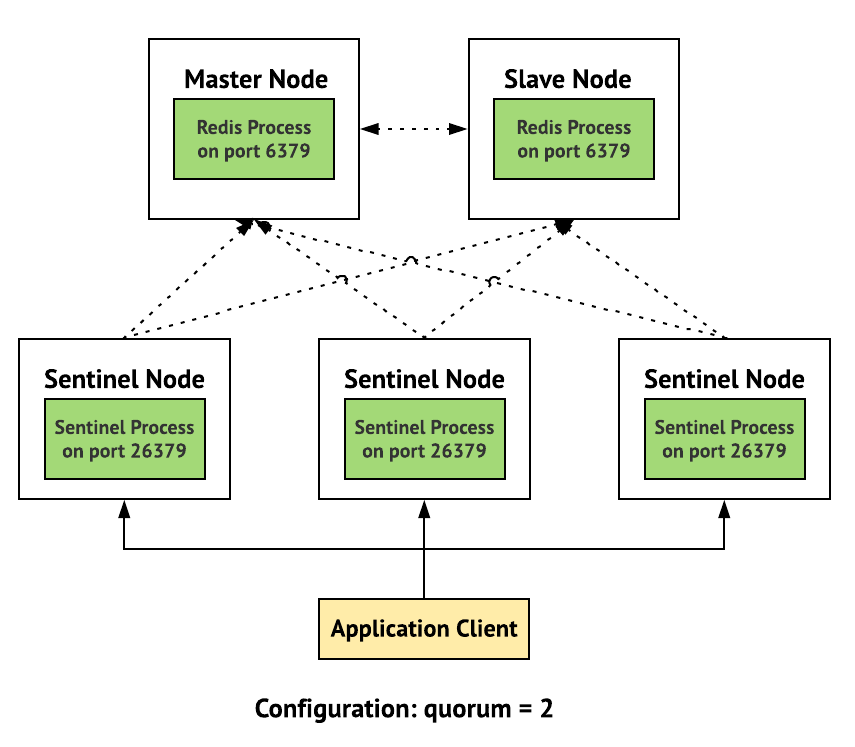 Sentinel Architecture
Sentinel Architecture
Sentinel은 보통 3대 이상의 홀수 개 인스턴스로 구성되며, 서로를 감시하면서 다음과 같이 동작합니다.
- 장애 감지: Sentinel 인스턴스들은 주기적으로 Master와 Replica 서버의 상태를 확인합니다. 특정 Master가 응답이 없으면 해당 Sentinel은 주관적으로 다운되었다고 판단합니다(SDOWN).
- 과반수 동의: 다른 Sentinel들에게도 해당 Master의 상태를 물어봅니다. 과반수 이상의 Sentinel이 다운에 동의하면 객관적인 장애로 최종 확정합니다(ODOWN).
- 리더 선출: 살아남은 Sentinel 중에서 리더를 선출하여 장애 조치 과정을 지휘하도록 합니다.
- 장애 조치(Failover):
- Sentinel 리더는 Replica 중 하나를 새로운 Master로 승격시킵니다.
- 나머지 Replica들이 새로운 Master를 바라보도록 설정합니다.
- 기존 Master가 다시 살아나면, 새로운 Master의 Replica로 편입시킵니다.
- 클라이언트 알림: Sentinel은 클라이언트에게 새로운 Master의 주소를 알려주어, 애플리케이션이 새로운 Master에 자동으로 연결될 수 있도록 돕습니다.
6.3. Cluster (분산 저장 및 수평 확장)
Sentinel이 서버의 장애 복구에 중점을 둔다면, Cluster는 데이터를 여러 서버에 분산 저장(Sharding)하여 성능과 용량을 수평적으로 확장하는 데 중점을 둡니다.
단일 Master 구조는 아무리 Sentinel을 사용해도 결국 쓰기 작업이 한 서버에 집중되므로, 메모리 용량과 처리량에 물리적인 한계가 존재합니다. Cluster는 이 한계를 극복하기 위해 데이터를 여러 Master 노드에 분산시킵니다.
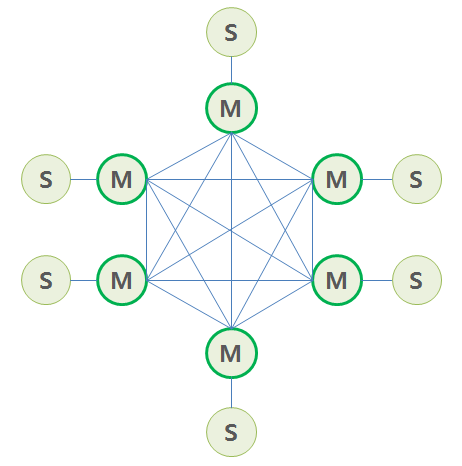 Redis Cluster Architecture
Redis Cluster Architecture
데이터 분산 방식: Hash Slot
Redis Cluster는 해시 슬롯(Hash Slot) 방식을 사용하여 데이터를 분산합니다.
- 전체 키 공간을 16,384개의 해시 슬롯으로 나눕니다.
- 각 Master 노드는 이 슬롯의 일부를 담당합니다.
- 데이터의 키를
CRC16해시 함수로 계산한 뒤 16,384로 나눈 나머지 값을 통해 어떤 슬롯에 속할지 결정합니다. - 클라이언트는 키에 해당하는 슬롯을 담당하는 노드로 직접 요청을 보냅니다.
만약 클라이언트가 잘못된 노드에 요청을 보내면, 해당 노드는 “이 키는 다른 노드(IP, Port)가 담당하고 있음” 이라는 MOVED 또는 ASK 리다이렉션 응답을 보냅니다. 클라이언트는 이 정보를 바탕으로 올바른 노드에 다시 요청을 보내고, 이후부터 해당 키 패턴에 대한 노드 정보를 캐싱하여 더 효율적으로 통신합니다.
7. 마치며
지금까지 Redis의 등장 배경부터 주요 특징, 그리고 안정적인 서비스를 위한 내부 아키텍처까지 자세히 살펴보았습니다.
이번 글을 작성하면서 Redis가 제공하는 기능뿐만 아니라, 그 이면에 숨겨진 동작 원리까지 깊이 있게 공부할 수 있었습니다. 특히 각 기능이 ‘왜’ 만들어졌는지, ‘어떤’ 문제를 해결하기 위해 도입되었는지를 고민해보면서 Redis를 만든 개발자들의 설계 철학을 간접적으로나마 경험할 수 있었던 뜻깊은 시간이었습니다.
- 왜 멀티 스레드가 아닌 싱글 스레드를 선택했는지
- 휘발성 메모리라는 한계를 딛고 어떻게 데이터 영속성을 보장하는지
- 트래픽이 늘어남에 따라 시스템을 어떻게 확장해야 하는지
이러한 물음들에 대해 이해하고 나니, Redis가 단순한 도구가 아닌 여러 문제를 해결하기 위해 끊임없이 진화해온 플랫폼임을 알게 되었던 것 같습니다.
앞으로 마주할 프로젝트에서 Redis를 사용하게 된다면, 이번 글에서 다룬 내용들을 바탕으로 더 깊이 이해하고, 상황에 맞게 올바르게 활용할 수 있도록 노력하겠습니다.